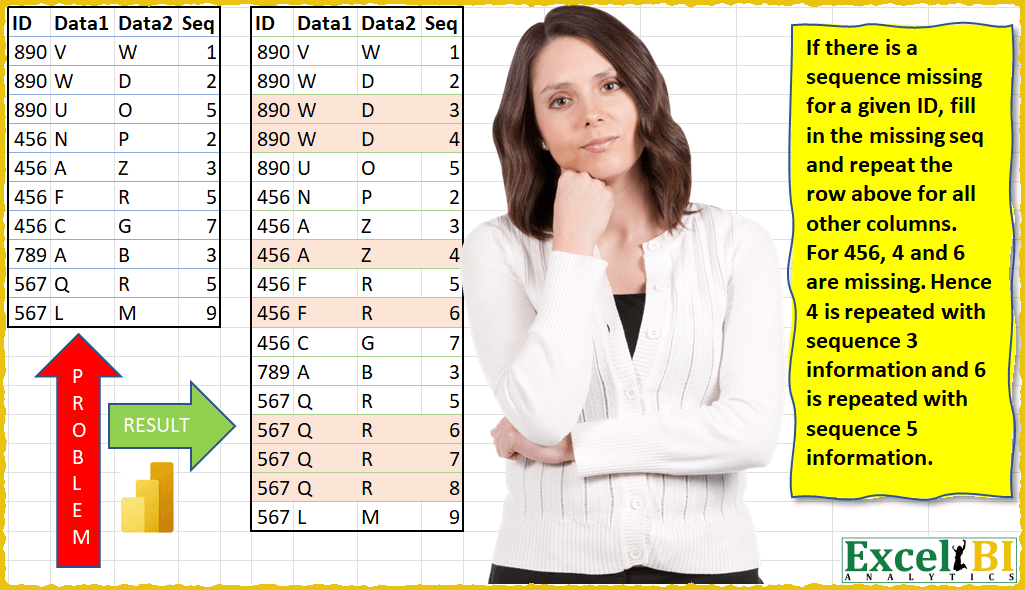
(Excel formulas also welcome) If there is a sequence missing for a given ID, fill in the missing sequence and repeat the row above for all other columns. For 456, 4 and 6 are missing. Hence 4 is repeated with sequence 3 information and 6 is repeated with sequence 5 information. For 890, 3 & 4 are missing, hence 3 & 4 are repeated with sequence 2 information.
📌 Challenge Details and Links
ExcelBI Power Query Challenge Number: 12
Challenge Difficulty: ⭐️⭐️⭐️⭐️
📥Download Sample File
📥Link to the solutions on LinkedIn
Solving the challenge of Fill Missing Sequences Per ID with Power Query
Power Query solution 1 for Fill Missing Sequences Per ID, proposed by Alejandro Simón 🇵🇦 🇪🇸:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
#"Sorted Rows" = Table.Sort(Source, {{"ID", Order.Ascending}, {"Seq", Order.Ascending}}),
Grouped = Table.Group(
#"Sorted Rows",
{"ID"},
{
{
"Count",
each
let
z = _,
a = Table.AddIndexColumn(z, "Idx", 0, 1),
b = Table.AddColumn(a, "Sig", each try a[Seq]{[Idx] + 1} - [Seq] - 1 otherwise 0),
c = Table.AddColumn(b, "Seq ", each {[Seq] .. [Seq] + [Sig]})
in
c
}
}
)[[Count]],
Expanded = Table.ExpandTableColumn(
Grouped,
"Count",
{"ID", "Data1", "Data2", "Seq "},
{"ID", "Data1", "Data2", "Seq"}
),
Solucion = Table.ExpandListColumn(Expanded, "Seq")
in
SolucionPower Query solution 2 for Fill Missing Sequences Per ID, proposed by Eric Laforce:
let
Source = Excel.CurrentWorkbook(){[Name="tData12"]}[Content],
Sort = Table.Sort(Source,{{"ID", Order.Ascending}, {"Seq", Order.Ascending}}),
Group =Table.Group(Sort, {"ID"}, {{"Data", each let
_Add_Index = Table.AddIndexColumn(_, "Index", 0,1),
_Add_ListSeq = Table.AddColumn(_Add_Index, "ListSeq",
each {[Seq]..([Seq]+(try _Add_Index[Seq]{[Index]+1} - [Seq] -1 otherwise 0))}),
_DelCol = Table.RemoveColumns(_Add_ListSeq, {"Seq", "Index"})
in Table.ExpandListColumn(_DelCol, "ListSeq")
}}),
Expand = Table.ExpandTableColumn(Group[[Data]], "Data",
{"ID", "Data1", "Data2", "ListSeq"}, {"ID", "Data1", "Data2", "Seq"})
in
Expand
Power Query solution 3 for Fill Missing Sequences Per ID, proposed by Eric Laforce:
let
Source = Excel.CurrentWorkbook(){[Name="tData12"]}[Content],
Group = Table.Group(Source, {"ID"}, {{"Data", each _, type table [ID=number, Data1=text, Data2=text, Seq=number]}}),
Transform = Table.TransformColumns(Group[[Data]], { {"Data", each let
_CompleteSeq = Table.FromList({List.Min(_[Seq])..List.Max(_[Seq])},
Splitter.SplitByNothing(), {"Seq"}, null, ExtraValues.Error),
_Join = Table.NestedJoin(_, {"Seq"}, _CompleteSeq, {"Seq"}, "1", JoinKind.RightOuter),
_Expand = Table.ExpandTableColumn(_Join, "1", {"Seq"}, {"Seq.1"}),
_FillDown = Table.FillDown(_Expand,{"ID", "Data1", "Data2"}),
_RemoveSeqOriginal = Table.RemoveColumns(_FillDown,{"Seq"})
in Table.RenameColumns(_RemoveSeqOriginal,{{"Seq.1", "Seq"}})
}
}),
Expand = Table.ExpandTableColumn(Transform, "Data", {"ID", "Data1", "Data2", "Seq"}, {"ID", "Data1", "Data2", "Seq"})
in
Expand
Power Query solution 4 for Fill Missing Sequences Per ID, proposed by 🇮🇷 Navid Esmaeilzadeh اسماعیل زاده:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
#"Changed Type" = Table.TransformColumnTypes(
Source,
{{"ID", Int64.Type}, {"Data1", type text}, {"Data2", type text}, {"Seq", Int64.Type}}
),
#"Grouped Rows" = Table.Group(
#"Changed Type",
{"ID"},
{{"Min", each List.Min([Seq]), type number}, {"Max", each List.Max([Seq]), type number}}
),
#"Added Custom" = Table.AddColumn(#"Grouped Rows", "Seq", each {[Min] .. [Max]}),
#"Expanded Seq" = Table.ExpandListColumn(#"Added Custom", "Seq"),
#"Removed Other Columns" = Table.SelectColumns(#"Expanded Seq", {"ID", "Seq"}),
Custom1 = Table.NestedJoin(
#"Removed Other Columns",
{"ID", "Seq"},
#"Changed Type",
{"ID", "Seq"},
"Removed Other Columns",
JoinKind.LeftOuter
),
#"Expanded Removed Other Columns" = Table.ExpandTableColumn(
Custom1,
"Removed Other Columns",
{"Data1", "Data2"},
{"Data1", "Data2"}
),
#"Sorted Rows" = Table.Sort(
#"Expanded Removed Other Columns",
{{"ID", Order.Descending}, {"Seq", Order.Ascending}}
),
#"Filled Down" = Table.FillDown(#"Sorted Rows", {"Data1", "Data2"}),
#"Removed Other Columns1" = Table.SelectColumns(#"Filled Down", {"ID", "Data1", "Data2", "Seq"})
in
#"Removed Other Columns1"Power Query solution 5 for Fill Missing Sequences Per ID, proposed by Matthias Friedmann:
let
Source = Excel.CurrentWorkbook(){[Name = "MissingSeq"]}[Content],
#"Grouped Rows" = Table.Group(
Source,
{"ID"},
{{"MinSeq", each List.Min([Seq]), type number}, {"MaxSeq", each List.Max([Seq]), type number}}
),
#"Added Custom" = Table.AddColumn(#"Grouped Rows", "Seq", each {[MinSeq] .. [MaxSeq]})[[ID],[Seq]],
#"Expanded Custom" = Table.ExpandListColumn(#"Added Custom", "Seq"),
#"Added Index" = Table.AddIndexColumn(#"Expanded Custom", "Index", 0, 1, Int64.Type),
#"Merged Queries" = Table.NestedJoin(
#"Added Index",
{"ID", "Seq"},
Source,
{"ID", "Seq"},
"Source",
JoinKind.LeftOuter
),
#"Expanded Source" = Table.ExpandTableColumn(#"Merged Queries", "Source", {"Data1", "Data2"}),
#"Sorted Rows" = Table.Sort(#"Expanded Source", {{"Index", Order.Ascending}})[[ID],[Data1],[Data2],[Seq]],
#"Filled Down" = Table.FillDown(#"Sorted Rows", {"Data1", "Data2"})
in
#"Filled Down"
Power Query solution 6 for Fill Missing Sequences Per ID, proposed by Venkata Rajesh:
let
Source = Data,
FullSeq = Table.ExpandListColumn(
Table.Group(Source, {"ID"}, {{"Sequence", each {List.Min([Seq]) .. List.Max([Seq])}}}),
"Sequence"
),
Output = Table.FillDown(
Table.ExpandTableColumn(
Table.AddColumn(
FullSeq,
"Custom",
each
let
_id = [ID],
_Seq = [Sequence]
in
Table.SelectRows(Source, each ([ID] = _id and [Seq] = _Seq))
),
"Custom",
{"Data1", "Data2"},
{"Data1", "Data2"}
),
{"Data1", "Data2"}
)
in
OutputPower Query solution 7 for Fill Missing Sequences Per ID, proposed by Venkata Rajesh:
let
Source = Data,
GroupbyID = Table.Group(Source, {"ID"}, {{"all", each _, type table [ID=nullable number, Data1=nullable text, Data2=nullable text, Seq=nullable number]}}),
MissingSeq = Table.AddColumn(GroupbyID, "Custom", each try Table.RenameColumns(Table.FromList(List.RemoveMatchingItems({List.Min([all] [Seq])..List.Max([all][Seq])},[all][Seq]), Splitter.SplitByNothing(), null, null, ExtraValues.Error),{{"Column1", "Seq"}} ) otherwise hashtag#table( {"Seq"}, { } )),
Result = Table.FillDown(Table.SelectColumns(Table.ExpandTableColumn(Table.AddColumn(MissingSeq, "Custom.1", each Table.Sort (Table.Combine({[all], [Custom]}),{{"Seq", Order.Ascending}})), "Custom.1", {"Data1", "Data2", "Seq"}, {"Data1", "Data2", "Seq"}),{"ID", "Data1", "Data2", "Seq"}),{"Data1", "Data2"})
in
Result
Power Query solution 8 for Fill Missing Sequences Per ID, proposed by Sandeep Marwal:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
#"Grouped Rows" = Table.Group(
Source,
{"ID"},
{
{
"Count",
(a) =>
[
Seq = Table.FromColumns({{a[Seq]{0} .. List.Last(a[Seq])}}),
#"Merged Queries" = Table.NestedJoin(
Seq,
{"Column1"},
a,
{"Seq"},
"Seq",
JoinKind.LeftOuter
),
#"Expanded Seq" = Table.ExpandTableColumn(
#"Merged Queries",
"Seq",
{"ID", "Data1", "Data2", "Seq"},
{"ID", "Data1", "Data2", "Seq.1"}
),
#"Removed Columns" = Table.RemoveColumns(#"Expanded Seq", {"Seq.1"}),
#"Filled Down" = Table.FillDown(#"Removed Columns", {"ID", "Data1", "Data2"})
][#"Filled Down"]
}
}
),
#"Expanded Count" = Table.ExpandTableColumn(
#"Grouped Rows",
"Count",
{"Column1", "Data1", "Data2"},
{"Column1", "Data1", "Data2"}
)
in
#"Expanded Count"Power Query solution 9 for Fill Missing Sequences Per ID, proposed by Sue Bayes:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
Group = Table.Group(
Source,
{"ID"},
{{"MinSeq", each List.Min([Seq]), type number}, {"MaxSeq", each List.Max([Seq]), type number}}
),
SeqList = Table.RemoveColumns(
Table.AddColumn(Group, "Seq", each {[MinSeq] .. [MaxSeq]}),
{"MinSeq", "MaxSeq"}
),
ExpandSeq = Table.ExpandListColumn(SeqList, "Seq"),
Sort = Table.Sort(ExpandSeq, {{"ID", Order.Ascending}, {"Seq", Order.Ascending}}),
Merge = Table.NestedJoin(Sort, {"ID", "Seq"}, Source, {"ID", "Seq"}, "Data", JoinKind.LeftOuter),
ExpandData = Table.ExpandTableColumn(Merge, "Data", {"Data1", "Data2"}, {"Data1", "Data2"}),
FillDown = Table.FillDown(ExpandData, {"Data1", "Data2"}),
ReOrder = Table.ReorderColumns(FillDown, {"ID", "Data1", "Data2", "Seq"}),
Type = Table.TransformColumnTypes(
ReOrder,
{{"ID", Int64.Type}, {"Data1", type text}, {"Data2", type text}, {"Seq", Int64.Type}}
)
in
TypePower Query solution 10 for Fill Missing Sequences Per ID, proposed by Hristo Tsenov:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
List = Table.ExpandListColumn(
Table.AddColumn(
Table.Group(
Source,
{"ID"},
{{"Min", each List.Min([Seq]), type number}, {"Max", each List.Max([Seq]), type number}}
),
"Seq",
each {[Min] .. [Max]}
),
"Seq"
),
Expand = Table.ExpandTableColumn(
Table.AddIndexColumn(
Table.NestedJoin(
List,
{"ID", "Seq"},
#"Source",
{"ID", "Seq"},
"Expanded Custom1",
JoinKind.LeftOuter
),
"Index",
1,
1,
Int64.Type
),
"Expanded Custom1",
{"Data1", "Data2"},
{"Data1", "Data2"}
),
Select = Table.SelectColumns(
Table.Sort(Table.FillDown(Expand, {"Data1", "Data2"}), {{"Index", Order.Ascending}}),
{"ID", "Data1", "Data2", "Seq"}
)
in
SelectPower Query solution 11 for Fill Missing Sequences Per ID, proposed by Solar Zhu:
let
Source = Excel.CurrentWorkbook(){[Name = "Source"]}[Content],
ColNames = Table.ColumnNames(Excel.CurrentWorkbook(){[Name = "Source"]}[Content]),
Rows = Table.Group(Source, {"ID"}, {{"Min", each List.Min([Seq])}, {"Max", each List.Max([Seq])}}),
AddSeqColumn = Table.AddColumn(Rows, "Seq", each {[Min] .. [Max]}),
ExpandSeq = Table.ExpandListColumn(AddSeqColumn, "Seq"),
Merge = Table.FillDown(
Table.ExpandTableColumn(
Table.AddColumn(
ExpandSeq,
"NewCol",
each
let
id = [ID],
Seq = [Seq]
in
Table.SelectRows(Source, each ([ID] = id and [Seq] = Seq))
),
"NewCol",
{"Data1", "Data2"}
),
{"Data1", "Data2"}
),
Result = Table.RemoveColumns(Merge, {"Min", "Max"})
in
ResultSolving the challenge of Fill Missing Sequences Per ID with Excel
Excel solution 1 for Fill Missing Sequences Per ID, proposed by John V.:
=LET(d,B3:B12,e,E3:E12,u,UNIQUE(d),
ls,MAP(u,LAMBDA(x,MIN(IF(d=x,e)))),
us,MAP(u,LAMBDA(x,MAX((d=x)*e))),
b,SCAN(,1+us-ls,LAMBDA(i,x,i+x)),
s,SEQUENCE(MAX(b))-1,y,VSTACK(0,b),
c,s-LOOKUP(s,y),
a,c+LOOKUP(s,y,ls),
f,MAKEARRAY(MAX(b),3,LAMBDA(r,c,LOOKUP(INDEX(a,r),e/(d=INDEX(LOOKUP(s,y,u),r)),INDEX(B3:D12,,c)))),
VSTACK(G2:J2,HSTACK(f,a)))Excel solution 2 for Fill Missing Sequences Per ID, proposed by محمد حلمي:
=REDUCE(B2:E2,UNIQUE(B3:B12),LAMBDA(a,d,LET(
v, FILTER(C3:E12,B3:B12=d),
m,MIN(v),
s, SEQUENCE(MAX(v)-m +1,,m),
r,XMATCH(s,INDEX(v,,3),-1),
VSTACK(a,IFNA(HSTACK(d,
INDEX(TAKE(v,,1), r),
INDEX(INDEX(v,,2), r),s),d)))))Excel solution 3 for Fill Missing Sequences Per ID, proposed by محمد حلمي:
=REDUCE(B2:E2,UNIQUE(B3:B12),
LAMBDA(a,v,
LET(
z,B3:E12,
id,TAKE(z,,1),
s,TAKE(z,,-1),
m,MINIFS(s,id,v),
q,SEQUENCE(MAXIFS(s,id,v)-m+1,,m),
VSTACK(a,HSTACK(
INDEX(z,XMATCH(v&q,id&s,-1),SEQUENCE(,3)),q)))))Excel solution 4 for Fill Missing Sequences Per ID, proposed by 🇰🇷 Taeyong Shin:
=LET(Id, UNIQUE(B3:B12),
idmin, MINIFS(E3:E12, B3:B12, Id),
idmax, MAXIFS(E3:E12, B3:B12, Id),
lookup, B3:B12 & E3:E12,
Thk, MAP(Id, idmax, idmin, LAMBDA(a,b,c,
Thunk(LET(seq, a & SEQUENCE(b-c+1, , c),
HSTACK( CHOOSEROWS(B3:D12, XMATCH(seq, lookup, -1)), seq-(a*10) )
))
)),
REDUCE(, Thk, LAMBDA(a,b, VSTACK(IFERROR(a(), a), b() ) ))
)
Thunk = LAMBDA(x, LAMBDA(x))Excel solution 5 for Fill Missing Sequences Per ID, proposed by 🇰🇷 Taeyong Shin:
=k-1),FILTER(e,u=k-1),,,-1),""))))
이 부분을 변수 j에 식으로 정의해 놓은 것이고
... DROP(z,-1),j(b,m,u,m,b)Excel solution 6 for Fill Missing Sequences Per ID, proposed by Duy Tùng:
=LET(b,B3:B12,e,E3:E12,u,DROP(REDUCE(0,UNIQUE(b),LAMBDA(x,y,LET(a,FILTER(e,b=y),VSTACK(x,IF({1,0},y,SEQUENCE(MAX(a)-MIN(a)+1,,@a)))))),1),f,LAMBDA(v,XLOOKUP(TAKE(u,,1)&DROP(u,,1),b&e,v,,-1)),VSTACK(B2:E2,HSTACK(TAKE(u,,1),f(C3:C12),f(D3:D12),DROP(u,,1))))Excel solution 7 for Fill Missing Sequences Per ID, proposed by Bhavya Gupta:
=LET(Data,B3:E12,
I,TAKE(Data,,1),
S,TAKE(Data,,-1),
U,UNIQUE(I),
Mx,XLOOKUP(U,I,S,,,-1),
Mn,XLOOKUP(U,I,S),
Rc,SCAN(0,Mx-Mn+1,LAMBDA(x,y,x+y)),
FI,XLOOKUP(SEQUENCE(MAX(Rc)),Rc,U,,1),
FS,SCAN(0,IF(VSTACK(FALSE,DROP(FI,1)=DROP(FI,-1)),,XLOOKUP(FI,U,Mn)),LAMBDA(a,b,IF(b,b,a+1))),
FD,CHOOSEROWS(DROP(DROP(Data,,1),,-1),SCAN(0,MATCH(FI&FS,I&S,0),LAMBDA(s,d,IFNA(d,s)))),
HSTACK(FI,FD,FS))Excel solution 8 for Fill Missing Sequences Per ID, proposed by Md. Zohurul Islam:
=LET(
rng,B3:E12,
id,UNIQUE(TAKE(rng,,1)),
A,REDUCE("",id,LAMBDA(p,q,LET(data,FILTER(rng,TAKE(rng,,1)=q),value,CHOOSECOLS(data,1,2,3),n,TAKE(data,,-1),mn,MIN(n),mx,MAX(n),seq,SEQUENCE(mx-mn+1,,mn),res,DROP(REDUCE("",seq,LAMBDA(y,x,VSTACK(y,XLOOKUP(x,n,value,,-1)))),1),rr,HSTACK(res,seq),ss,VSTACK(p,rr),ss))),
&B,DROP(A,1),
B)