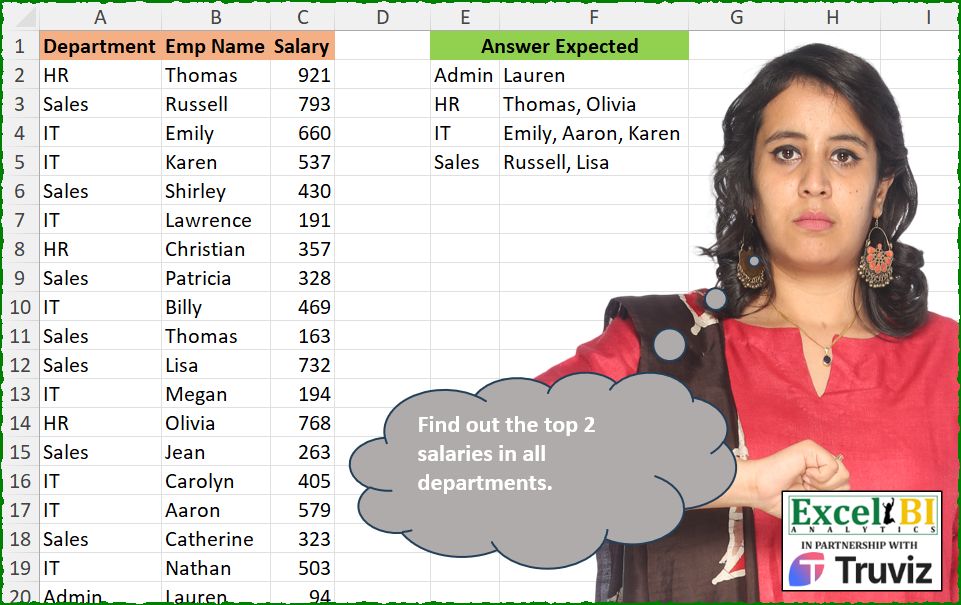
Find out the top 2 salaries in all departments.
📌 Challenge Details and Links
ExcelBI Excel Challenge Number: 543
Challenge Difficulty: ⭐️
📥Download Sample File
📥Link to the solutions on LinkedIn
Solving the challenge of Top Two Department Salaries with Power Query
Power Query solution 1 for Top Two Department Salaries, proposed by John V.:
let
S = Excel.CurrentWorkbook(){0}[Content],
R = Table.Group(S, "Department", {"Emp", each
let
M = List.MaxN([Salary], 2),
A = Table.SelectRows(_, each List.Contains(M , [Salary]))[Emp Name]
in
Text.Combine(A, ", ")
})
in
Table.Sort(R, "Department")
Blessings!
Power Query solution 2 for Top Two Department Salaries, proposed by Kris Jaganah:
let
S = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
A = Table.Group(
S,
{"Department"},
{
"Employee",
each [
a = List.Min(List.MaxN([Salary], 2)),
b = Table.ToRows([[Emp Name], [Salary]]),
c = List.Select(b, (x) => x{1} >= a),
d = List.Zip(List.Sort(c, {{each _{1}, 1}, {each _{0}, 0}})){0},
e = Text.Combine(d, ", ")
][e]
}
),
B = Table.Sort(A, {"Department", 0})
in
BPower Query solution 3 for Top Two Department Salaries, proposed by Kris Jaganah:
let
S = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
A = Table.Group(
S,
{"Department"},
{
"All",
each [
a = Table.AddRankColumn(_, "Rk", {"Salary", 1}, [RankKind = RankKind.Dense]),
b = Table.SelectRows(a, (x) => x[Rk] <= 2),
c = Text.Combine(Table.Sort(b, {{"Rk", 0}, {"Emp Name", 0}})[Emp Name], ", ")
][c]
}
),
B = Table.Sort(A, {"Department", 0})
in
BPower Query solution 4 for Top Two Department Salaries, proposed by Aditya Kumar Darak 🇮🇳:
let
Source = Excel.CurrentWorkbook(){[Name = "data"]}[Content],
Group = Table.Group(
Source,
"Department",
{
"Employee",
each [
M = List.Last(List.MaxN([Salary], 2)),
S = Table.MaxN(_, "Salary", (f) => f[Salary] >= M)[Emp Name],
R = Text.Combine(S, ", ")
][R]
}
),
Sort = Table.Sort(Group, "Department")
in
SortPower Query solution 5 for Top Two Department Salaries, proposed by Alejandro Simón 🇵🇦 🇪🇸:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
Sol = Table.Sort(
Table.Group(
Source,
{"Department"},
{
{
"Answer",
each
let
a = _,
b = Table.Sort(a, {"Salary", 1}),
c = List.Combine(
List.Transform(List.FirstN(b[Salary], 2), each List.PositionOf(b[Salary], _, 2))
),
d = List.Transform(c, each b[Emp Name]{_}),
e = Text.Combine(d, ", ")
in
e
}
}
),
"Department"
)
in
SolPower Query solution 6 for Top Two Department Salaries, proposed by Hussein SATOUR:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
GroupDeps = Table.Group(Source, {"Department"}, {{"All", each _}}),
SortDeps = Table.Sort(GroupDeps, {{"Department", 0}}),
Names = Table.AddColumn(
SortDeps,
"Custom",
each Text.Combine(
Table.SelectRows(Table.AddRankColumn([All], "Rank", {"Salary", 1}), each [Rank] < 3)[Emp Name],
", "
)
),
FinalResult = Table.RemoveColumns(Names, {"All"})
in
FinalResultPower Query solution 7 for Top Two Department Salaries, proposed by Abdallah Ally:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
Sort = Table.Sort(Source, {{"Department", 0}, {"Salary", 1}, {"Emp Name", 0}}),
Transform = List.Transform(
List.Distinct(Sort[Department]),
each [
a = Table.SelectRows(Sort, (x) => x[Department] = _)[Salary],
b = List.FirstN(List.Distinct(a), 2),
c = Table.SelectRows(Sort, each List.Contains(b, [Salary]))[Emp Name],
d = [Department = _, Employees = Text.Combine(c, ", ")]
][d]
),
Result = Table.FromRecords(Transform)
in
ResultPower Query solution 8 for Top Two Department Salaries, proposed by Ramiro Ayala Chávez:
let
S = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
a = Table.Group(
S,
{"Department"},
{
"Names",
each Text.Combine(
Table.Combine(
List.Transform(
Table.MaxN(
Table.Sort(Table.Group(_, {"Salary"}, {"G", each _}), {"Salary", 1}),
"Salary",
2
)[G],
each Table.Sort(_, {"Emp Name", 0})
)
)[Emp Name],
", "
)
}
),
Sol = Table.Sort(a, {"Department", 0})
in
SolPower Query solution 9 for Top Two Department Salaries, proposed by Antriksh Sharma:
let
Source = Raw,
SortedRows = Table.Sort(Source, {{"Salary", Order.Descending}}),
GroupedRows = Table.Group(
SortedRows,
{"Department"},
{
{
"Names",
each
let
TopSalaries = List.FirstN([Salary], 2),
Result = Table.SelectRows(_, each List.Contains(TopSalaries, [Salary]))
in
Text.Combine(Result[Emp Name], ", "),
type text
}
}
)
in
GroupedRowsPower Query solution 10 for Top Two Department Salaries, proposed by Ahmed Ariem:
let
Source = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
from = Table.TransformColumnTypes(
Source,
{{"Department", type text}, {"Emp Name", type text}, {"Salary", Int64.Type}}
),
Gr = Table.Group(
from,
{"Department"},
{
{
"tmp",
(x) =>
[
f = (w, z, p) => Table.Sort(w, {{"Salary", z}, {"Emp Name", p}}),
a = Table.LastN(f(x, 0, 0), 2)[Salary],
b = f(Table.SelectRows(x, (s) => List.ContainsAny({s[Salary]}, a)), 1, 0)[Emp Name],
c = Text.Combine(b, ", ")
][c]
}
}
),
Sort = Table.Sort(Gr, {{"Department", 0}})
in
SortSolving the challenge of Top Two Department Salaries with Excel
Excel solution 1 for Top Two Department Salaries, proposed by Bo Rydobon 🇹🇭:
=GROUPBY(A2:A20,C2:C20-10^6&B2:B20,LAMBDA(x,LET(s,-LEFT(x,7),ARRAYTOTEXT(FILTER(MID(x,8,9),s<=SMALL(s,MIN(ROWS(x),2)))))),,0)
=LET(d,A2:A20,s,C2:C20,u,SORT(UNIQUE(d)),HSTACK(u,MAP(u,LAMBDA(v,LET(y,d=v,ARRAYTOTEXT(FILTER(B2:B20,y*(s>=LARGE(y*s,MIN(SUM(--y),2))))))))))Excel solution 2 for Top Two Department Salaries, proposed by Bo Rydobon 🇹🇭:
=GROUPBY(A2:A20,C2:C20-10^6&B2:B20,LAMBDA(x,LET(s,SORT(x),ARRAYTOTEXT(MID(TAKE(s,@MATCH(INDEX(LEFT(s,7),MIN(ROWS(x),2)),LEFT(s,7))),8,9)))),,0)
=LET(z,SORT(A2:C20,2),g,GROUPBY(CHOOSECOLS(z,1,3),INDEX(z,,2),ARRAYTOTEXT,,0,-2),GROUPBY(TAKE(g,,1),DROP(g,,2),LAMBDA(x,ARRAYTOTEXT(TAKE(x,2))),,0))Excel solution 3 for Top Two Department Salaries, proposed by John V.:
=LET(d,A2:A20,s,C2:C20,GROUPBY(d,B2:B20,ARRAYTOTEXT,,0,,s>=MAP(d,LAMBDA(x,LARGE(s*(d=x),2)))))Excel solution 4 for Top Two Department Salaries, proposed by محمد حلمي:
=LET(d,
A2:A20,
u,
SORT(
UNIQUE(
d
)
),
HSTACK(u,
MAP(u,
LAMBDA(a,
LET(x,
d=a,
i,
x*C2:C20,
ARRAYTOTEXT(
FILTER(B2:B20,
x*(i>=LARGE(
UNIQUE(
i
),
2
)))))))))Excel solution 5 for Top Two Department Salaries, proposed by محمد حلمي:
=LET(
d,
A2:A20,
u,
SORT(
UNIQUE(
d
)
),
HSTACK(
u,
MAP(
u,
LAMBDA(
a,
ARRAYTOTEXT(
TAKE(
SORT(
FILTER(
B2:C20,
d=a
),
2,
-1
),
2,
1
)
)
)
)
)
)Excel solution 6 for Top Two Department Salaries, proposed by 🇰🇷 Taeyong Shin:
=LET(
d,
A2:A20,
f,
LAMBDA(
x,
LET(
g,
GROUPBY(
B2:B20,
C2:C20,
SUM,
,
0,
-2,
d=@x
),
n,
DROP(
g,
,
1
),
TEXTJOIN(
", ",
,
T(
TAKE(
g,
XMATCH(
2,
XMATCH(
n,
n
),
-1,
-1
)
)
)
)
)
),
GROUPBY(
d,
d,
f,
,
0
)
)Excel solution 7 for Top Two Department Salaries, proposed by Kris Jaganah:
=LET(
m,
A2:A20,
p,
SORT(
UNIQUE(
m
)
),
HSTACK(
p,
MAP(
p,
LAMBDA(
x,
LET(
a,
FILTER(
HSTACK(
B2:B20,
C2:C20
),
m=x
),
b,
TAKE(
a,
,
-1
),
c,
TAKE(
a,
,
1
),
IFERROR(
ARRAYTOTEXT(
FILTER(
c,
b>=LARGE(
UNIQUE(
b
),
2
)
)
),
c
)
)
)
)
)
)Excel solution 8 for Top Two Department Salaries, proposed by Julian Poeltl:
=LET(D,A2:A20,N,B2:B20,S,C2:C20,U,SORT(UNIQUE(D)),HSTACK(U,MAP(U,LAMBDA(A,LET(F,FILTER(HSTACK(N,S),D=A),D,DROP(F,,1),TEXTJOIN(", ",,DROP(FILTER(F,D>IFERROR(LARGE(UNIQUE(D),3),0)),,-1)))))))Excel solution 9 for Top Two Department Salaries, proposed by Timothée BLIOT:
=LET(A,A2:A20,B,B2:B20,C,C2:C20,D,SORT(UNIQUE(A)),HSTACK(D,MAP(D,LAMBDA(x,ARRAYTOTEXT(FILTER(FILTER(B,A=x),IFERROR(FILTER(C,A=x)>=LARGE(FILTER(C,A=x),2),1)))))))Excel solution 10 for Top Two Department Salaries, proposed by Nikola Z Grujicic - Nikola Ž Grujičić:
=LET(
a,
A2:C20,
b,
SORTBY(
a,
CHOOSECOLS(
a,
3
),
-1
),
d,
CHOOSECOLS(
b,
1
),
e,
CHOOSECOLS(
b,
2
),
f,
TOCOL(
UNIQUE(
d
),
3
),
g,
MAP(
f,
LAMBDA(
ff,
TEXTJOIN(
", ",
,
FILTER(
e,
d=ff
)
)
)
),
h,
HSTACK(
f,
g
),
i,
SORTBY(
h,
CHOOSECOLS(
h,
1
)
),
prvo,
CHOOSECOLS(
i,
1
),
drugo,
CHOOSECOLS(
i,
2
),
z,
FIND(
", ",
drugo
),
zz,
IFERROR(
FIND(
",",
drugo,
z+1
),
LEN(
drugo
)+1
),
HSTACK(
prvo,
LEFT(
drugo,
zz-1
)
)
)Excel solution 11 for Top Two Department Salaries, proposed by Hussein SATOUR:
=LET(d,
A2:A20,
s,
C2:C20,
u,
UNIQUE(
SORT(
d
)
),
v,
MAP(u,
LAMBDA(x,
ARRAYTOTEXT(FILTER(B2:B20,
(d=x)*(IFERROR(
s>LARGE(
UNIQUE(
FILTER(
s,
d=x
)
),
3
),
1
)))))),
HSTACK(
u,
v
))Excel solution 12 for Top Two Department Salaries, proposed by Oscar Mendez Roca Farell:
=LET(d, A2:A20, u, SORT(UNIQUE(d)), c, C2:C20, HSTACK(u, MAP(u, LAMBDA(a, LET(F, LAMBDA(i, FILTER(i, d=a)), TEXTJOIN(", ", 1, REPT(F(B2:B20), F(c)>=IFERROR(LARGE(F(c), 2), 1))))))))Excel solution 13 for Top Two Department Salaries, proposed by Duy Tùng:
=LET(
a,
A2:A20,
c,
C2:C20,
GROUPBY(
a,
B2:B20,
ARRAYTOTEXT,
,
0,
,
VLOOKUP(
a,
IFERROR(
GROUPBY(
a,
c,
LAMBDA(
x,
LARGE(
x,
2
)
)
),
0
),
2,
)<=c
)
)Excel solution 14 for Top Two Department Salaries, proposed by Sunny Baggu:
=LET(
_u, SORT(UNIQUE(A2:A20)),
HSTACK(
_u,
MAP(
_u,
LAMBDA(x,
LET(
_a, SORT(FILTER(B2:C20, A2:A20 = x), 2, -1),
_b, TOROW(TAKE(UNIQUE(TAKE(_a, , -1)), 2)),
_c, ARRAYTOTEXT(
FILTER(TAKE(_a, , 1), MMULT(N(TAKE(_a, , -1) = _b), {1; 1}))
),
IFERROR(_c, UNIQUE(TAKE(_a, , 1)))
)
)
)
)
)Excel solution 15 for Top Two Department Salaries, proposed by LEONARD OCHEA 🇷🇴:
=LET(a,A2:A20,b,B2:B20,c,C2:C20,GROUPBY(a,b,ARRAYTOTEXT,,0,,IFERROR(MAP(a,c,LAMBDA(x,y,OR(y=LARGE(FILTER(c,a=x),{1;2})))),1)))
With a forgotten function AGGREGATE
=LET(a,A2:A20,b,B2:B20,c,C2:C20,GROUPBY(a,b,ARRAYTOTEXT,,0,,IFERROR(MAP(a,c,LAMBDA(x,y,OR(AGGREGATE(14,6,IF(a=x,c,z),{1;2})=y))),1)))Excel solution 16 for Top Two Department Salaries, proposed by Anshu Bantra:
=LET(
depts_,
SORT(
UNIQUE(
A2:A20
)
),
names_,
MAP(
depts_,
LAMBDA(
d,
TEXTJOIN(
", ",
,
CHOOSECOLS(
TAKE(
SORT(
FILTER(
$B$2:$C$20,
$A$2:$A$20 = d
),
2,
-1
),
2
),
1
)
)
)
),
HSTACK(
depts_,
names_
)
)Excel solution 17 for Top Two Department Salaries, proposed by Pieter de B.:
=LET(a,A2:A20,u,SORT(UNIQUE(a)),HSTACK(u,MAP(u,LAMBDA(x,ARRAYTOTEXT(FILTER(B2:B20,IFERROR(C2:C20>=LARGE(FILTER(C2:C20,a=x),2),1)*(a=x)))))))Excel solution 18 for Top Two Department Salaries, proposed by Hamidi Hamid:
=LET(x,SORTBY(A2:C20,C2:C20,-1),z,DROP(x,,-1),f,DROP(GROUPBY(TAKE(z,,1),TAKE(z,,-1),ARRAYTOTEXT),-1),e,REDUCE(,TAKE(f,,-1),LAMBDA(a,b,VSTACK(a,TEXTSPLIT(b,",")))),uu,SORT(UNIQUE(TAKE(x,,1))),HSTACK(uu,BYROW(IFERROR(TAKE(e,,2),""),ARRAYTOTEXT)))Excel solution 19 for Top Two Department Salaries, proposed by Asheesh Pahwa:
=DROP(
REDUCE(
"",
SORT(
UNIQUE(
A2:A20
)
),
LAMBDA(
x,
y,
VSTACK(
x,
LET(
f,
FILTER(
B2:C20,
A2:A20=y
),
s,
SORT(
f,
2,
-1
),
t,
TAKE(
s,
,
-1
),
HSTACK(
y,
TEXTJOIN(
",",
1,
REDUCE(
"",
TAKE(
t,
2
),
LAMBDA(
a,
v,
VSTACK(
a,
FILTER(
TAKE(
s,
,
1
),
t=v
)
)
)
)
)
)
)
)
)
),
1
)Excel solution 20 for Top Two Department Salaries, proposed by ferhat CK:
=LET(d,SORT(UNIQUE(A2:A20)),dz,MAP(d,LAMBDA(x,LET(a,GROUPBY(A2:B20,C2:C20,MAX,0,0,,A2:A20=x),b,--DROP(a,,2),IFERROR(TEXTJOIN(", ",TRUE,FILTER(TAKE(DROP(a,,1),,1),(b=LARGE(b,1))+(b=LARGE(b,2)))),DROP(DROP(a,,1),,-1))))),HSTACK(d,dz))Excel solution 21 for Top Two Department Salaries, proposed by JvdV -:
=LET(a,A2:A20,c,C2:C20,GROUPBY(a,B2:B20,ARRAYTOTEXT,,0,,COUNTIFS(a,a,c,">"&c)<2))Excel solution 22 for Top Two Department Salaries, proposed by Tolga Demirci, PMP, PMI-ACP, MOS-Expert:
=MAP(SORT(UNIQUE(A2:A20),,1),LAMBDA(z,LET(b,ISNUMBER(MAP(A2:A20,C2:C20,LAMBDA(x,y,XLOOKUP(z,x,y)))),TEXTJOIN(", ",,LET(m,FILTER(C2:C20,b),UNIQUE(MAP(TOCOL(IFERROR(LARGE(m,{1,2}),LARGE(m,{1}))),LAMBDA(p,TEXTJOIN(", ",,LET(a,MAP(m,FILTER(B2:B20,b),LAMBDA(o,i,XLOOKUP(p,o,i))),FILTER(a,NOT(ISNA(a)))))))))))))Excel solution 23 for Top Two Department Salaries, proposed by Imam Hambali:
=LET(
a,
SORT(
A2:C20,
{1,
3},
{1,
-1}
),
b,
--(TAKE(
a,
,
1
) = VSTACK(
0,
DROP(
TAKE(
a,
,
1
),
-1
)
)),
c,
SCAN(
0,
b,
LAMBDA(
x,
y,
IF(
y=0,
1,
y+x
)
)
),
d,
FILTER(
a,
c<3
),
GROUPBY(
TAKE(
d,
,
1
),
CHOOSECOLS(
d,
2
),
ARRAYTOTEXT,
0,
0
)
)Excel solution 24 for Top Two Department Salaries, proposed by Eddy Wijaya:
=LET(
db,A2:C20,
dept_u,UNIQUE(TAKE(db,,1)),
SORT(HSTACK(dept_u,
MAP(dept_u,LAMBDA(m,
LET(
m_db,FILTER(db,CHOOSECOLS(db,1)=m),
top,IFERROR(LARGE(TAKE(m_db,,-1),2),TAKE(m_db,,-1)),
TEXTJOIN(", ",,FILTER(CHOOSECOLS(m_db,2),TAKE(m_db,,-1)>=top))))))))Excel solution 25 for Top Two Department Salaries, proposed by Milan Shrimali:
=MAP(SORT(UNIQUE(A2:A20),1,1),LAMBDA(X,HSTACK(X,LET(A,SORT(FILTER($B$2:$C$20,$A$2:$A$20=X),2,0),RNK,HSTACK(A,MAP(CHOOSECOLS(A,2),LAMBDA(X,RANK(X,CHOOSECOLS(A,2))))),JOIN(",",FILTER(FILTER(RNK,(CHOOSECOLS(RNK,3)=1)+(CHOOSECOLS(RNK,3)=2)),{1,0,0}))))))Excel solution 26 for Top Two Department Salaries, proposed by Francesco Bianchi 🇮🇹:
=HSTACK(
SORT(UNIQUE(A2:A20)),
BYROW(
SORT(UNIQUE(A2:A20)),
LAMBDA(y,
LET(
a, $A$2:$C$20,
b, FILTER(a, CHOOSECOLS(a, 1) = y),
c, LARGE(CHOOSECOLS(b, 3), 2),
d, FILTER(b, CHOOSECOLS(b, 3) >= c),
IFERROR(
ARRAYTOTEXT(CHOOSECOLS(SORTBY(d, CHOOSECOLS(d, 3), -1, CHOOSECOLS(d, 2), 1), 2)),
CHOOSECOLS(b, 2)
)
)
)
)
)Excel solution 27 for Top Two Department Salaries, proposed by RIJESH T.:
=LET(dep,
UNIQUE(
SORT(
A2:A20
)
),
emp,
MAP(dep,
LAMBDA(d,
TEXTJOIN(", ",
,
FILTER($B$2:$B$20,
($A$2:$A$20=d)*($C$2:$C$20>=IFERROR(LARGE(FILTER($A$2:$C$20,
($A$2:$A$20=d)),
2),
C2:C20)))))),
HSTACK(
dep,
emp
))Excel solution 28 for Top Two Department Salaries, proposed by Ben Warshaw:
=LET(
pivot,
PIVOTBY(
B2:B20,
A2:A20,
C2:C20,
SUM,
,
0,
,
0
),
labels,
SORT(
UNIQUE(
A2:A20
)
),
ID,
MATCH(
labels,
CHOOSEROWS(
pivot,
1
)
),
Output,
WRAPCOLS(
REDUCE(labels,
ID,
LAMBDA(st,
curr,
VSTACK(
st,
LET(
a,
DROP(
INDEX(
pivot,
,
curr
),
1
),
c,
TAKE(
SORT(
FILTER(
a,
a<>""
),
,
-1
),
2
),
d,
FILTER(DROP(
INDEX(
pivot,
,
1
),
1
),
(a=INDEX(
c,
1
))),
e,
IFERROR(FILTER(DROP(
INDEX(
pivot,
,
1
),
1
),
(a=INDEX(
c,
2
))),
""),
ARRAYTOTEXT(
VSTACK(
d,
e
)
)
)
)
)),
ROWS(
labels
)
),
Output
)Excel solution 29 for Top Two Department Salaries, proposed by Shaik Jafar Hussain:
=
CONCATENATEX(
TOPN(2,
SUMMARIZE(Table1, Table1[Department], Table1[Emp Name],"Salary", SUM(Table1[Salary])),
[Salary] , DESC),
Table1[Emp Name]&":"&FORMAT([Salary], "#,##")&" ")Solving the challenge of Top Two Department Salaries with Python
Python solution 1 for Top Two Department Salaries, proposed by Konrad Gryczan, PhD:
import pandas as pd
path = "543 Top 2 Salaries.xlsx"
input = pd.read_excel(path, usecols="A:C")
test = pd.read_excel(path, usecols="E:F", skiprows=1, nrows=4, header=None, names=['Department', 'Emp Name'])
result = (
input
.groupby('Department')['Salary']
.nlargest(2)
.reset_index()
.merge(input, on=['Department', 'Salary'])
.sort_values(['Department', 'Salary', 'Emp Name'], ascending=[True, False, True])
.groupby('Department')['Emp Name']
.agg(', '.join)
.reset_index()
)
print(result.equals(test)) # True
Solving the challenge of Top Two Department Salaries with Python in Excel
Python in Excel solution 1 for Top Two Department Salaries, proposed by Alejandro Campos:
df = xl("A1:C20", headers=True)
df_sorted = df.sort_values(by=['Department', 'Salary'], ascending=[True, False])
top_2_salaries = df_sorted.groupby('Department').head(2).reset_index(drop=True)
grouped_df = top_2_salaries.groupby('Department')['Emp Name'].apply(', '.join).reset_index()
grouped_df.columns = ['Dept', 'Emp Name']
grouped_df
Python in Excel solution 2 for Top Two Department Salaries, proposed by Abdallah Ally:
df = xl("A1:C20", headers=True)
# Perform data manipulation
df = df.sort_values(
by=['Department', 'Salary', 'Emp Name'], ascending=[True, False, True]
)
values = []
for dep in df['Department'].unique():
df_dep = df[df['Department'] == dep]
salaries = df_dep['Salary'].unique()
if len(salaries) > 2:
employees = df_dep['Emp Name'][df_dep['Salary'] > salaries[2]]
else:
employees = df_dep['Emp Name'][df_dep['Salary'] >= salaries[-1]]
values.append([dep, ', '.join(employees)])
df = pd.DataFrame(data=values, columns=df.columns[:2])
df
Python in Excel solution 3 for Top Two Department Salaries, proposed by Anshu Bantra:
df = xl("A1:C20", headers=True)
df.sort_values(by=['Department', 'Salary'], ascending=[True, False])
answer_expected = {}
for dept in sorted(df['Department'].unique()):
top_emp_names = df[df['Department'] == dept].head(2)['Emp Name'].tolist()
answer_expected[dept] = ', '.join(top_emp_names)
pd.DataFrame(
list(answer_expected.items()),
columns=['Department', 'Emp Names']
)
Python in Excel solution 4 for Top Two Department Salaries, proposed by Antriksh Sharma:
Python for excel:
df.sort_values(by=['Department', 'Salary'], ascending=[True, False], inplace=True)
top_n_salaries = df.groupby(by=['Department']).head(2)
df_join = pd.merge(top_n_salaries, df, on=['Department', 'Salary'], how='left')
df_join.drop(columns='Emp Name_x', inplace=True)
df_join.rename(columns={'Emp Name_y': 'Emp Name'}, inplace= True)
result = df_join.groupby(['Department'], as_index = False).agg({'Emp Name': ', '.join})
Solving the challenge of Top Two Department Salaries with R
R solution 1 for Top Two Department Salaries, proposed by Konrad Gryczan, PhD:
library(tidyverse)
library(readxl)
path = "Excel/543 Top 2 Salaries.xlsx"
input = read_excel(path, range = "A1:C20")
test = read_excel(path, range = "E2:F5", col_names = FALSE)
names(test) = c("Department", "emps")
result <- input %>%
slice_max(Salary, n = 2, by = Department) %>%
arrange(Department, desc(Salary), `Emp Name`) %>%
summarise(emps = paste(`Emp Name`, collapse = ", "), .by = Department)
identical(result, test)
# [1] TRUE
&&