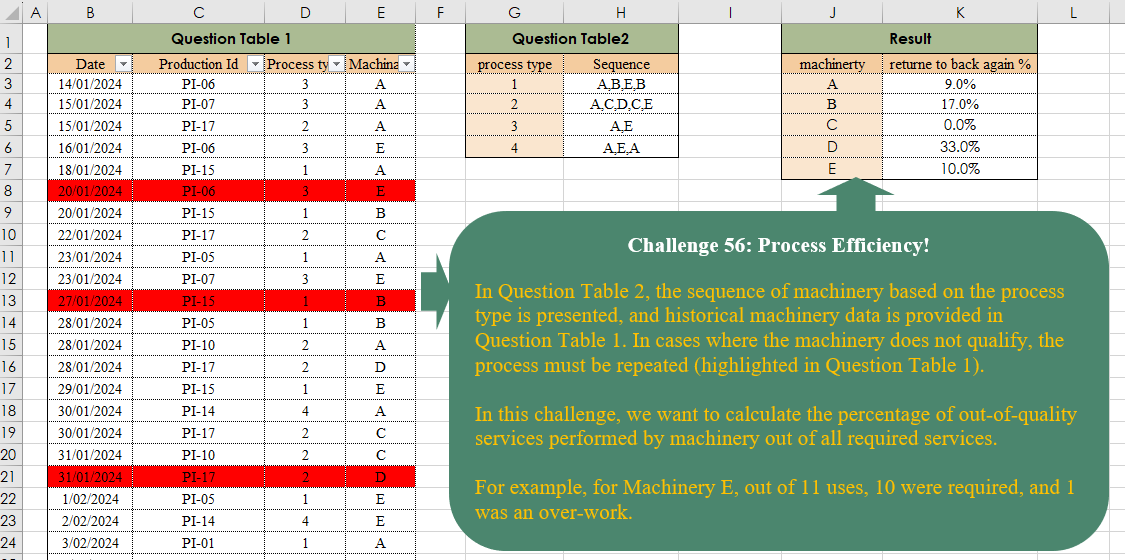
In Question Table 2, the sequence of machinery based on the process type is presented, and historical machinery data is provided in Question Table 1. In cases where the machinery does not qualify, the process must be repeated (highlighted in Question Table 1). In this challenge, we want to calculate the percentage of out-of-quality services performed by machinery out of all required services. For example, for Machinery E, out of 11 uses, 10 were required, and 1 was an over-work.
📌 Challenge Details and Links
Challenge Number: 56
Challenge Difficulty: ⭐⭐
📥Download Sample File
📥Link to the solutions on LinkedIn
Solving the challenge of Process Efficiency! with Power Query
Power Query solution 1 for Process Efficiency!, proposed by Aditya Kumar Darak 🇮🇳:
let
Data = Excel.CurrentWorkbook(){[Name = "data"]}[Content],
Seq = Excel.CurrentWorkbook(){[Name = "seq"]}[Content],
Split = Table.TransformColumns(Seq, {"Sequence", each Text.Split(_, ",")}),
Group = Table.Group(
Data,
"Production Id",
{
"Seq",
each [
Ma = [Machinary],
T = List.Transform(
Split[Sequence],
(f) => [
s = f,
d1 = List.Difference(Ma, f),
d2 = List.Difference(f, Ma),
c = List.Count(d2 & d1)
]
),
R = List.Min(T, 0, (f) => f[c])[[s], [d1]]
][R]
}
),
Expand = Table.ExpandRecordColumn(Group, "Seq", {"s", "d1"}, {"s", "d1"}),
Correct = List.Combine(Expand[s]),
Incorrect = List.Combine(Expand[d1]),
UniqueMac = List.Sort(List.Distinct(List.Union(Split[Sequence]))),
Record = List.Transform(
UniqueMac,
each [
C = List.Count(List.Select(Correct, (f) => f = _)),
I = List.Count(List.Select(Incorrect, (f) => f = _)),
R = [Machinery = _, #"Return to Back %" = I / C]
][R]
),
Return = Table.FromRecords(Record)
in
ReturnPower Query solution 2 for Process Efficiency!, proposed by Alexis Olson:
let
T1 = Excel.CurrentWorkbook(){[Name = "Table1"]}[Content],
T2 = Table.TransformColumns(
Table.RenameColumns(
Excel.CurrentWorkbook(){[Name = "Table3"]}[Content],
{{"process type", "Process type"}}
),
{{"Sequence", each Text.Split(_, ",")}}
),
GroupId = Table.Group(T1, {"Process type", "Production Id"}, {{"Machinary", each [Machinary]}}),
Merge = Table.Join(GroupId, {"Process type"}, T2, {"Process type"}),
Diff = Table.AddColumn(Merge, "Diff", each List.Difference([Machinary], [Sequence])),
GroupMach = Table.Group(T1, {"Machinary"}, {{"Total", each Table.RowCount(_)}}),
Extra = Table.AddColumn(
GroupMach,
"Extra",
each List.Count(List.Select(List.Combine(Diff[Diff]), (x) => [Machinary] = x))
),
Ratio = Table.AddColumn(Extra, "Ratio", each [Extra] / ([Total] - [Extra]), Percentage.Type),
Result = Table.Sort(
Table.SelectColumns(Ratio, {"Machinary", "Ratio"}),
{{"Machinary", Order.Ascending}}
)
in
ResultSolving the challenge of Process Efficiency! with Excel
Excel solution 1 for Process Efficiency!, proposed by Bo Rydobon 🇹🇭:
=LET(L,
LAMBDA(
l,
c,
s,
[i],
IF(
COUNT(
SEARCH(
SUBSTITUTE(
s,
",",
"*"
),
c
)
),
l(
l,
REDUCE(
c,
TEXTSPLIT(
s,
","
),
LAMBDA(
a,
v,
SUBSTITUTE(
a,
v,
i+1,
1
)
)
),
s,
i+1
),
c
)
),m,
E3:E42,
g,
GROUPBY(
D3:D42,
m,
LAMBDA(
x,
ARRAYTOTEXT(
x
)
),
,
0
),u,
MAP(
TAKE(
g,
,
1
),
LAMBDA(
i,
L(
L,
INDEX(
g,
i,
2
),
INDEX(
H3:H6,
i
)
)
)
),
v,
TEXTSPLIT(
ARRAYTOTEXT(
u
),
,
", "
),r,
GROUPBY(
v,
v,
ROWS,
,
0,
,
,
v>="A"
),
IFERROR(r/(COUNTIF(
m,
TAKE(
r,
,
1
)
)-r),
r))Excel solution 3 for Process Efficiency!, proposed by Bo Rydobon 🇹🇭:
=LET(
p,
DROP(
REDUCE(
0,
H3:H6,
LAMBDA(
a,
v,
VSTACK(
a,
IF(
{1,
0},
@+G6:v,
TEXTSPLIT(
v,
,
","
)
)
)
)
),
1
),
q,
GROUPBY(
p,
TAKE(
p,
,
1
),
ROWS,
,
0
),
t,
TAKE(
q,
,
1
),
m,
INDEX(
q,
,
2
),
v,
DROP(
q,
,
2
), n,
COUNTIFS(
D3:D42,
t,
E3:E42,
m
),
g,
GROUPBY(
m,
n*{1,
0}-v*VLOOKUP(
t,
GROUPBY(
t,
INT(
n/v
),
MIN
),
2
),
SUM,
,
0
),
HSTACK(
q,
n
)
)Excel solution 4 for Process Efficiency!, proposed by محمد حلمي:
=LET(e,
E3:E42,
c,
C3:C42,
d,
D3:D42,
u,
SORT(
UNIQUE(
e
)
),
i,
SUM(
COUNTIFS(
e,
u,
c,
UNIQUE(
c
),
d,
UNIQUE(
d
)
)
),
i/(COUNTIF(
e,
u
)-i))Excel solution 5 for Process Efficiency!, proposed by Julian Poeltl:
=LET(T,
B3:E42,
TT,
G3:H6,
P,
CHOOSECOLS(
T,
2
),
PT,
CHOOSECOLS(
T,
3
),
M,
TAKE(
T,
,
-1
),
PTT,
TAKE(
TT,
,
1
),
PTS,
TAKE(
TT,
,
-1
),
U,
UNIQUE(
P
),
XT,
XLOOKUP(
U,
P,
PT
),
MR,
CONCAT(
XLOOKUP(
XT,
PTT,
PTS
)
),
UU,
SORT(
UNIQUE(
M
)
),
R,
MAP(UU,
LAMBDA(A,
LET(C,
COUNTIFS(
M,
A
),
L,
LEN(
MR
)-LEN(
SUBSTITUTE(
MR,
A,
""
)
),
(C-L)/L))),
HSTACK(
UU,
R
))Excel solution 6 for Process Efficiency!, proposed by Kris Jaganah:
=LET(
a,
SORT(
UNIQUE(
E3:E42
)
),
REDUCE(
{"machinerty",
"returne to back again %"},
a,
LAMBDA(
x,
y,
VSTACK(
x,
LET(
b,
E3:E42,
c,
GROUPBY(
HSTACK(
D3:D42,
C3:C42
),
b,
COUNTA,
,
0,
,
,
b=y
),
d,
TOROW(
a
),
e,
INDEX(
LEN(
H3:H6
)-LEN(
SUBSTITUTE(
H3:H6,
d,
)
),
TAKE(
c,
,
1
),
MATCH(
y,
d,
0
)
),
f,
DROP(
c,
,
2
),
HSTACK(
y,
ROUND(
SUM(
f-e
)/SUM(
e
),
2
)
)
)
)
)
)
)Excel solution 7 for Process Efficiency!, proposed by Sunny Baggu:
=LET(
_u,
SORT(
UNIQUE(
E3:E42
)
), _c1,
BYROW(
SORTBY(
C3:E42,
C3:C42
),
LAMBDA(
a,
CONCAT(
a
)
)
), _e1,
LAMBDA(
z,
SCAN(
0,
VSTACK(
1,
N(
DROP(
z,
1
) <> DROP(
z,
-1
)
)
),
LAMBDA(
a,
v,
IF(
v = 0,
a + 1,
v
)
)
)
), _c2,
DROP(
REDUCE(
"", SORT(
UNIQUE(
C3:C42
)
), LAMBDA(x,
y,
VSTACK(x,
LET(_d,
SORT(
BYROW(
FILTER(
D3:E42,
C3:C42 = y
),
LAMBDA(
a,
CONCAT(
a
)
)
)
),
_d & _e1(_d))))
), 1
), _v,
DROP(
REDUCE(
"", SEQUENCE(
ROWS(
G3:G6
)
), LAMBDA(x,
y, VSTACK(
x, LET(
_c,
SORT(
INDEX(
G3:H6,
y,
1
) & TEXTSPLIT(
INDEX(
G3:H6,
y,
2
),
,
","
)
), _c & _e1(SORT(
INDEX(
G3:H6,
y,
1
) & TEXTSPLIT(
INDEX(
G3:H6,
y,
2
),
,
","
)
))
)
)
)
), 1
), _c3,
IFNA(
XMATCH(
_c2,
_v
),
0
), HSTACK(
_u,
MAP(
_u,
LAMBDA(
g,
LET(
_c4,
FILTER(
_c3,
ISNUMBER(
SEARCH(
g,
_c2
)
)
),
ROUND(
100 * SUM(
N(
_c4 = 0
)
) / SUM(
N(
_c4 <> 0
)
),
0
)
)
)
)
)
)